Newton polynomial
In the mathematical field of numerical analysis, a Newton polynomial, named after its inventor Isaac Newton, is the interpolation polynomial for a given set of data points in the Newton form. The Newton polynomial is sometimes called Newton's divided differences interpolation polynomial because the coefficients of the polynomial are calculated using divided differences.
For any given set of data points, there is only one polynomial (of least possible degree) that passes through all of them. Thus, it is more appropriate to speak of "the Newton form of the interpolation polynomial" rather than of "the Newton interpolation polynomial". Like the Lagrange form, it is merely another way to write the same polynomial.
Contents |
Definition
Given a set of k + 1 data points

where no two xj are the same, the interpolation polynomial in the Newton form is a linear combination of Newton basis polynomials
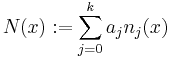
with the Newton basis polynomials defined as
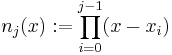
for 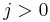 and
and 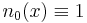 . The coefficients are defined as
. The coefficients are defined as
![a_j�:= [y_0,\ldots,y_j]](/2012-wikipedia_en_all_nopic_01_2012/I/b491d0408158e036e9d4e317aaee6e03.png)
where
![[y_0,\ldots,y_j]](/2012-wikipedia_en_all_nopic_01_2012/I/6daef1a01980a186b9c9b04125727b67.png)
is the notation for divided differences.
Thus the Newton polynomial can be written as
![N(x) = [y_0] %2B [y_0,y_1](x-x_0) %2B \cdots %2B [y_0,\ldots,y_k](x-x_0)(x-x_1)\cdots(x-x_{k-1}).](/2012-wikipedia_en_all_nopic_01_2012/I/ace3f8ce40c2aded63771a4e8f791263.png)
The Newton Polynomial above can be expressed in a simplified form when 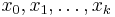 are arranged consecutively with equal space. Introducing the notation
are arranged consecutively with equal space. Introducing the notation 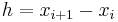 for each
for each 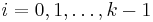 and
and 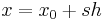 , the difference
, the difference 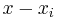 can be written as
can be written as 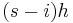 . So the Newton Polynomial above becomes:
. So the Newton Polynomial above becomes:
![N(x)= [y_0] %2B [y_0,y_1]sh %2B \cdots %2B [y_0,\ldots,y_k] s (s-1) \cdots (s-k%2B1){h}^{k}](/2012-wikipedia_en_all_nopic_01_2012/I/f4ecbd02cff20a4612b739dcd1bb02f0.png)
![= \sum_{i=0}^{k}s(s-1) \cdots (s-i%2B1){h}^{i}[y_0,\ldots,y_i]= \sum_{i=0}^{k}{s \choose i}i!{h}^{i}[y_0,\ldots,y_i]](/2012-wikipedia_en_all_nopic_01_2012/I/116e15794339c4778659a81a7a11740e.png)
![N(x)= \sum_{i=0}^{k}{s \choose i}i!{h}^{i}[y_0,\ldots,y_i]](/2012-wikipedia_en_all_nopic_01_2012/I/0d968596193a64ed2ad8db479a9b62bc.png)
is called the Newton Forward Divided Difference Formula.
If the nodes are reordered as 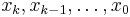 , the Newton Polynomial becomes:
, the Newton Polynomial becomes:
![N(x)=[y_k]%2B[{y}_{k}, {y}_{k-1}](x-{x}_{k})%2B\cdots%2B[{y}_{k},\ldots,{y}_{0}](x-{x}_{k})(x-{x}_{k-1})\cdots(x-{x}_{1})](/2012-wikipedia_en_all_nopic_01_2012/I/b2467520a5f3d4388ba98c0a1c0482c4.png)
If 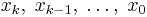 are equally spaced with x=
are equally spaced with x=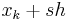 and
and 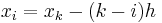 for
for 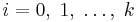 , then,
, then,
![N(x)= [{y}_{k}]%2B [{y}_{k}, {y}_{k-1}]sh%2B\cdots%2B[{y}_{k},\ldots,{y}_{0}]s(s%2B1)\cdots(s%2Bk-1){h}^{k}={(-1)}^{i}\sum_{i=0}^{k}{-s \choose i}i!{h}^{i}[{y}_{k},\ldots,{y}_{k-i}]](/2012-wikipedia_en_all_nopic_01_2012/I/db2a76a3003e96cbf14259095591d137.png)
![N(x)=\sum_{i=0}^{k}{(-1)}^{i}{-s \choose i}i!{h}^{i}[{y}_{k},\ldots,{y}_{k-i}]](/2012-wikipedia_en_all_nopic_01_2012/I/e9416ec60031dbb23241ce109bc9e1db.png)
is called the Newton Backward Divided Difference Formula.
Significance
Newton's formula is of interest because it is the straightforward and natural differences-version of Taylor's polynomial. Taylor's polynomial tells where a function will go, based on its y value, and its derivatives (its rate of change, and the rate of change of its rate of change, etc.) at one particular x value. Newton's formula is Taylor's polynomial based on finite differences instead of instantaneous rates of change.
Addition of new points
As with other difference formulas, the degree of a Newton's interpolating polynomial can be increased by adding more terms and points without discarding existing ones. Newton's form has the simplicity that the new points are always added at one end: Newton's forward formula can add new points to the right, and Newton's backwards formula can add new points to the left. Unfortunately, the accuracy of polynomial interpolation depends on how close the interpolated point is to the middle of the x values of the set of points used; as Newton's form always adds new points at the same end, an increase in degree cannot be used to increase the accuracy anywhere but at that end. Gauss, Stirling, and Bessel all developed formulae to remedy that problem.
Gauss's formula alternately adds new points at the left and right ends, thereby keeping the set of points centered near the same place (near the evaluated point). When so doing, it uses terms from Newton's formula, with data points and x values re-named in keeping with one's choice of what data point is designated as the 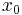 data point.
data point.
Stirling's formula remains centered about a particular data point, for use when the evaluated point is nearer to a data point than to a middle of two data points. Bessel's formula remains centered about a particular middle between two data points, for use when the evaluated point is nearer to a middle than to a data point. They achieve that by sometimes using the average of two differences where Newton's or Gauss's would use just one difference. Stirling's does that in odd-degree terms; Bessels does that in even-degree terms. Calculating and averaging two differences need not involve extra work, since it can be done by formula, in advance—the expression for the averaged difference is not more complicated than that of the simple difference.
Strengths and weaknesses of various formulae
The suitability of Stirling's, Bessel's and Gauss's formulae depends on 1) the importance of the small accuracy gain given by average differences; and 2) if greater accuracy is necessary, whether the interpolated point is closer to a data point or to a middle between two data points.
In general, the difference methods can be a good choice when one does not know how many points, what degree of interpolating polynomial, will be needed for the desired accuracy, and when one wants to look first at linear and other low-degree interpolation, successively judging accuracy by the difference in the results of two successive polynomial degrees. Lagrange's formula (not a difference formula) allows that also, but going to the next higher degree without re-doing work requires that each term's value be recorded—not a problem with a computer, but maybe awkward with a calculator.
Other than that, Lagrange is easier to calculate than the difference methods, and is (probably rightly) regarded by many as the best choice when one already knows what polynomial degree will be needed. And when all the interpolation will be done at one x value, with only the data points' y values varying from one problem to another, Lagrange's formula becomes so much more convenient that it begins to be the only choice to consider.
Lagrange's formula's ease of calculation is best achieved by its "barycentric forms". Its 2nd barycentric form might be the most efficient of all when using a computer, but its 1st barycentric form might be more convenient when using a calculator.
Accuracy
When a particular data point is designated as , then as the evaluated point approaches that data point, the difference formula terms after the constant term tend toward zero. Therefore, Stirling's formula is at its best in the region where it is less needed. Bessel's is at its best when the evaluated point is near the middle between two data points, and therefore Bessel's is at its best when the added accuracy is most needed. So, Bessel's formula could be said to be the most consistently accurate difference formula, and, in general, the most consistently accurate of the familiar polynomial interpolation formulas.
It should be added that, when Bessel's or Stirling's gains a little accuracy over Gauss's and Lagrange's, it would be unusual for that extra accuracy to be needed. No one should quit using Lagrange's or Gauss's because of it.
When, with Stirling's or Bessel's, the last term used includes the average of two differences, then one more point is being used than Newton's or other polynomial interpolations would use for the same polynomial degree. So, in that instance, Stirling's or Bessel's is not putting an N-1 degree polynomial through N points, but is, instead, trading equivalence with Newton's for better centering and accuracy, giving those methods sometimes potentially greater accuracy, for a given polynomial degree, than other polynomial interpolations.
The other difference formulas, such as those of Stirling, Bessel and Gauss, can be derived from Newton's, using Newton's terms, with data points and x values renamed in keeping with the choice of x zero, and based on the fact that they must add up to the same sum value as Newton's (With Stirling that is so when polynomial degree is even. With Bessel's that is so when polynomial degree is odd).
General case
For the special case of 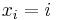 , there is a closely related set of polynomials, also called the Newton polynomials, that are simply the binomial coefficients for general argument. That is, one also has the Newton polynomials
, there is a closely related set of polynomials, also called the Newton polynomials, that are simply the binomial coefficients for general argument. That is, one also has the Newton polynomials 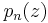 given by
given by
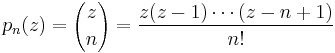
In this form, the Newton polynomials generate the Newton series. These are in turn a special case of the general difference polynomials which allow the representation of analytic functions through generalized difference equations.
Main idea
Solving an interpolation problem leads to a problem in linear algebra where we have to solve a system of linear equations. Using a standard monomial basis for our interpolation polynomial we get the very complicated Vandermonde matrix. By choosing another basis, the Newton basis, we get a system of linear equations with a much simpler lower triangular matrix which can be solved faster.
For k + 1 data points we construct the Newton basis as
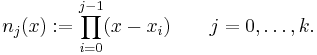
Using these polynomials as a basis for 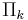 we have to solve
we have to solve
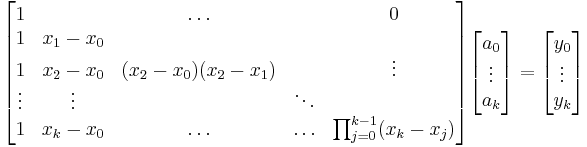
to solve the polynomial interpolation problem.
This system of equations can be solved recursively by solving
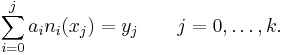
Taylor polynomial
The limit of the Newton polynomial if all nodes coincide is a Taylor polynomial, because the divided differences become derivatives.
![\lim_{(x_0,\dots,x_n)\to(z,\dots,z)}
f[x_0] %2B f[x_0,x_1]\cdot(\xi-x_0) %2B \dots %2B f[x_0,\dots,x_n]\cdot(\xi-x_0)\cdot\dots\cdot(\xi-x_{n-1})](/2012-wikipedia_en_all_nopic_01_2012/I/b0f283d0d50767876b0c64c11e93ece2.png)
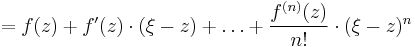
Application
As can be seen from the definition of the divided differences new data points can be added to the data set to create a new interpolation polynomial without recalculating the old coefficients. And when a data point changes we usually do not have to recalculate all coefficients. Furthermore if the xi are distributed equidistantly the calculation of the divided differences becomes significantly easier. Therefore the Newton form of the interpolation polynomial is usually preferred over the Lagrange form for practical purposes, although, in actual fact (and contrary to widespread claims), Lagrange, too, allows calculation of the next higher degree interpolation without re-doing previous calculations—and is considerably easier to evaluate.
Example
The divided differences can be written in the form of a table. For example, for a function 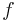 is to be interpolated on points
is to be interpolated on points  . Write
. Write
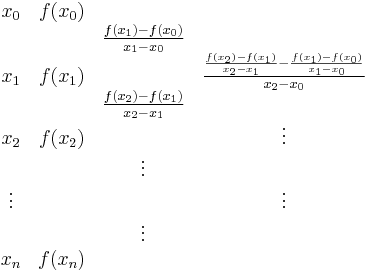
Then the interpolating polynomial is formed as above using the topmost entries in each column as coefficients.
For example, suppose we are to construct the interpolating polynomial to 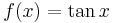 using divided differences, at the points
using divided differences, at the points
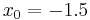 |
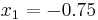 |
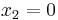 |
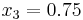 |
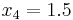 |
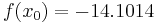 |
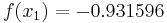 |
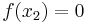 |
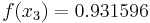 |
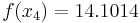 |
Using six digits of accuracy, we construct the table

Thus, the interpolating polynomial is
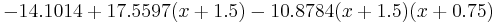
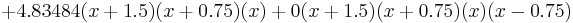
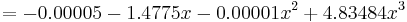
Given more digits of accuracy in the table, the first and third coefficients will be found to be zero.
See also
- Newton series
- Neville's schema
- Polynomial interpolation
- Lagrange form of the interpolation polynomial
- Bernstein form of the interpolation polynomial
- Hermite interpolation